Anomaly Detection: Approccio Pratico
Cos’è l’Anomaly Detection?
L’anomalia è un cambiamento inaspettato che si verifica durante lo svolgimento di un normale processo. Possono essere positive o negative, possono alterare il funzionamento del processo ed inoltre possono portare ad errori di valutazione.
La rilevazione delle anomalie (anomaly detection) viene utilizzata appositamente per rilevare questi comportamenti, ossia quei dati/punti che si discostano dal resto dei punti del dataset.
Le imprese attualmente ritengono di grande importanza la rilevazione delle anomalie in quanto acquisendo grandi quantità di dati (molti di essi rimangono in disuso), possono definire piani d’azione strategica, rilevare eventuali frodi, avere visione della cyber security, ma soprattutto garantire l’affidabilità dei processi di lavorazione nel caso dei settori industriali.
Il tema dell’anomaly detection prende sempre più piede in ogni ambito. Ad oggi, ci avvaliamo di tecnologie come l’utilizzo del machine learning che permette alle aziende di analizzare l’andamento delle loro strategie, individuare opportunità e minacce che garantirebbero un vantaggio competitivo.
Pensiamo, ad esempio, alla possibilità non solo di riuscire a rilevare un’anomalia, ma addirittura di prevederla, consentendo di agire tempestivamente sul percorso per il raggiungimento del nostro obiettivo.
Agire tempestivamente, o meglio prevedere un evento, evita l’insorgere di problemi complessi da risolvere che potrebbero causare danni di grandi dimensioni.
Se ragionassimo in ottica industriale prendendo in esempio un’impresa che produce motori per veicoli a plurimotore, un guasto a uno di essi, comporterebbe dei danni molto considerevoli soprattutto per gli ingenti investimenti fatti.
L’errore di lavorazione può essere attribuibile a diversi fattori legati prettamente a un errore di sistema e non ad uno umano. Durante il percorso di lavorazione sono evidentemente mancati dei segnali che permettevano di intercettare degli errori, come ad esempio dei picchi di temperatura. Senza gli strumenti necessari, pur avendo acquisito una vasta mole di dati, risulterebbe comunque difficile se non addirittura impossibile scovare anomalie.
La presenza di un sistema di rilevazione consente il monitoraggio costante di tutte quelle variabili come la temperatura, vibrazioni, pressioni, suono, ecc., che possono incidere sull’operato della macchina e prevenire eventuali guasti.
Nei metodi di anomaly detection ci avvaliamo di sistemi di modellizzazione e apprendimento automatico che in completa autonomia sono in grado di rilevare anomalie tramite l’analisi dati. Questi sistemi riescono ad individuare le variabili che condizionano il nostro business, evitando l’insorgere di problemi complessi da risolvere e danni ingenti.
Durante il percorso di lavorazione sono mancati dei segnali che permettevano di intercettare degli errori come possono essere dei picchi di temperatura. Con l’acquisizione di grandi moli di dati senza degli strumenti in grado di individuarli, una piccola deviazione è impossibile da trovare.
La presenza di un sistema di anomaly detection permette il monitoraggio costante di tutte quelle variabili come la temperatura, le vibrazioni, le pressioni, i suoni, ecc., che possono incidere sull’operato della macchina e prevenire eventuali guasti.
I sistemi di rilevazione delle anomalie si avvalgono di algoritmi di modellazione e apprendimento automatico che in completa autonomia riescono a rilevare anomalie. Questi sistemi riesco a individuare le variabili che suggestionano il nostro business e il nostro sistema produttivo.
Case Study
Il caso studio che andremo a presentare riguarda l’anomaly detection nelle fasi di lavorazione di un macchinario. Cogliere tali disfunzioni, che possono dipendere da diversi fattori esterni, permette di interrompere un processo di lavorazione errato riducendo anche gli impatti sul piano economico.
Il dataset, su cui verrà svolta l’analisi, è basato su dati anonimizzati per questioni di privacy, e su di esso saranno testati più modelli di classificazione, per poter inquadrare il migliore in questo caso specifico.
Procederemo l’analisi partendo da modelli più semplici per poi passere a modelli ritenuti molto efficienti e precisi. I modelli di classificazione saranno:
- Regressione Logistica
- Linear Discriminant Analysis
- XGBoost
Iniziamo dal modello di regressione logistica, il più semplice, ma che può comunque restituire risultati affidabili ed esaustivi.
Regressione Logistica
Il dataset su cui svolgeremo la nostra analisi e costituito da 86 variabili in cui figura una variabile Target, qualitativa di valori 0 e 1, che indicano rispettivamente lo stato di attività o di fermo del macchinario.
Una volta caricato il dataset, procediamo con l’analisi tramite regressione logistica (in quanto siamo dinanzi a una variabile dipendente dicotomica) con l’obiettivo di valutare la probabilità con cui l’osservazione può generare l’uno o l’altro valore della variabile dipendente.
library(readr)
anomaly_detection <- read_csv("anomaly_detection.csv")
attach(anomaly_detection)
library(glmnet) anomaly<-glm(Target~.,data=anomaly_detection,family = binomial(link = logit)) summary(anomaly)
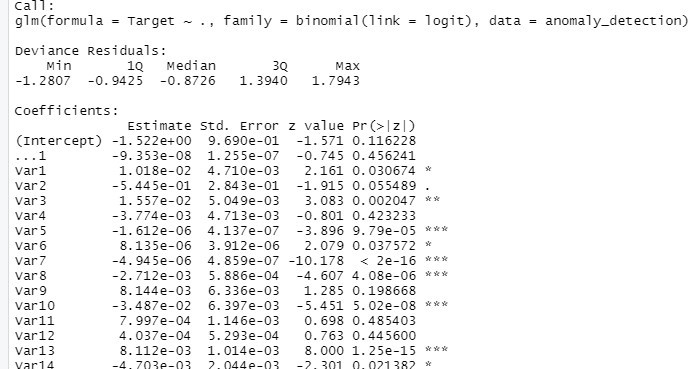
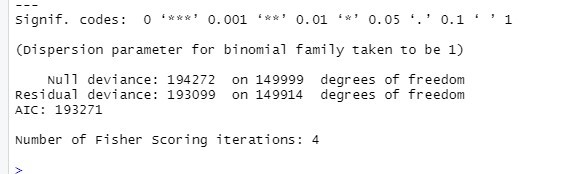
Dal summary() riscontriamo che alcune variabili risultano più significative di altre, ciò significa che incidono maggiormente sul manifestarsi dell’evento. Sotto i valori dei coefficienti ritroviamo i residui di invalidità, di anomalie e l’AIC (misura stimata della qualità di ciascun modello secondo un’insieme di dati, minore è il suo valore maggiore è la capacità di adattamento). Una volta analizzata la regressione, suddividiamo il dataset originale in training e test set. Nel training set consideriamo solo parte delle osservazioni totali (circa il 70%), necessarie per l’addestramento del modello, mentre tramite il test set valutiamo l’efficienza del modello confrontando i valori predetti con i valori reali.
library(ISLR) dataset<-anomaly_detection[,-1] sample <- sample(c(TRUE, FALSE), nrow(dataset), replace=TRUE, prob=c(0.7,0.3)) train <- dataset[sample, ] test<- dataset[!sample, ] anomaly<-glm(Target~.,data=train,family = binomial(link = logit)) prev<-predict(anomaly,test,type = "response")
Disegnando una matrice di confusione testiamo l’affidabilità del nostro modello e un metodo che possiamo utilizzare è l’utilizzo di soglie. Fissando una soglia di 0.5 (corrispondente al 50% della probabilità restituita dal modello), si ottengono delle previsioni per la variabile Target sul test set.
predict_reg<- ifelse(prev>0.5,1,0) table(predict_reg,test$Target)
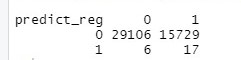
L’attenzione ricade sui falsi positivi, che rappresentano l’errata rilevazione di un errore e che portano ad un blocco non necessario della lavorazione.
classification_metrics <- function(
actual, forecast_prob,
min_soglia = 0, max_soglia = 100, step = 0.1,
get_plots = TRUE
){
actual_is_binary <- isTRUE(all(unique(actual) %in% c(0,1))) & isTRUE(length(unique(actual)) == 2)
if(!actual_is_binary) stop("Il vettore actual deve essere binario, con modalita' {0,1}")
if(isTRUE(base::all(as.numeric(forecast_prob) <= 1))){
warning("Tutti i valori di forecast_prob sono minori di 1. Moltiplico per 100.")
forecast_prob <- 100*as.numeric(forecast_prob)
}
stopifnot(base::all(
is.numeric(min_soglia),
is.numeric(max_soglia),
is.numeric(step)
))
vettore_soglie <- seq(from = min_soglia, to = max_soglia, by = step)
actual <- factor(actual, levels = c("1", "0"))
res <- purrr::map(vettore_soglie, function(soglia_singola){
forecast_bin <- ifelse((forecast_prob >= soglia_singola) %in% TRUE, 1, 0)
forecast_bin <- factor(forecast_bin, levels = c("1", "0"))
mc <- table(
"Forecast" = forecast_bin,
"Actual" = actual
) %>% as.data.frame.matrix()
tp <- mc[1,1]
fp <- mc[1,2]
fn <- mc[2,1]
tn <- mc[2,2]
accuracy <- (tp + tn)/sum(mc, na.rm = TRUE)
accuracy_perc <- round(100*accuracy, digits = 2)
precision <- tp / (tp + fp)
precision_perc <- round(100*precision, digits = 2)
recall <- tp / (tp + fn) # Recall/Sensitivity = True Positive Rate (TPR)
recall_perc <- round(100*recall, digits = 2)
fscore <- 2*(precision * recall)/(precision + recall)
fscore_perc <- round(100*fscore, digits = 2)
specificity <- tn / (tn + fp) # Specificity = True Negative Rate (TNR)
specificity_perc <- round(100*specificity, digits = 2)
fall_out <- fp / (fp + tn)
fall_out_perc <- round(100*fall_out, digits = 2)
return(data.frame(
"soglia" = soglia_singola,
"tp" = tp,
"fp" = fp,
"fn" = fn,
"tn" = tn,
"accuracy" = accuracy_perc,
"precision" = precision_perc,
"recall" = recall_perc,
"fscore" = fscore_perc,
"specificity" = specificity_perc,
"fall_out" = fall_out_perc,
stringsAsFactors = FALSE
))
})
res <- data.table::rbindlist(res)
res <- as.data.frame(res)
return(res)
}
library(dplyr) View(classification_metrics(test$Target, prev, step = 0.1)) predict_reg517<- ifelse(prev>0.517,1,0) table(predict_reg517,test$Target)
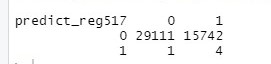
Avvalendosi di un’apposita tabella che mostra le metriche per ogni soglia di criticità, viene individuata quella che permette di avere il minor numero di falsi positivi e di massimizzare contemporaneamente i veri positivi. Nell’analisi di riferimento è stato riscontrato che la miglior soglia è pari al 51,7% che posta una riduzione di falsi positivi a 1.
Procedendo con ulteriori analisi riscontriamo che sono presenti valori non bilanciati di 0 e 1 all’interno della variabile Target, si procede al riequilibrio tramite diversi metodi.
Considerato che il dataset è sbilanciato, prima di addentrarci nella ricerca del modello che restituisce i risultati migliori, si procede con l’applicazione di diverse metodologie per la gestione di questa problematica:
- undersampling
- oversampling
Undersampling
I valori della variabile Target possono essere bilanciati riducendo il numero degli 0 tramite il metodo dell’undersampling o sotto-campionamento.
Vengono creati, di conseguenza, due sotto-dataset:
- uno contenete solo valori target=1
- uno contenente solo valori target=0
table(anomaly_detection$Target) data1<-subset(anomaly_detection,anomaly_detection$Target==1) data0<-subset(anomaly_detection,anomaly_detection$Target==0)
Successivamente si costruisce un dataset prendendo tutti gli 1 (che sono meno degli 0, di norma è sempre così) e solamente un numero di 0 pari al numero di 1.
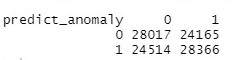
table(anomaly_detection$Target) set.seed(12345) undersample0= sample(1:nrow(data0), nrow(data1) , replace=FALSE) undersample0 anomalynew=rbind.data.frame(data0[undersample0,],data1) anomalynew table(anomalynew$Target) library(caTools) splitt <- sample.split(anomalynew,SplitRatio = 0.8) train2 <- subset(anomalynew, split = "TRUE") test2 <- subset(anomalynew, split = "FALSE") anomaly2<-glm(Target~.,data=train2,family = binomial(link = logit)) anomalypredict<-predict(anomaly2,test2,type = "response") head(anomalypredict) View(classification_metrics(test2$Target, predict_anomaly, step = 0.1)) predict_anomaly<-ifelse(anomalypredict>0.5,1,0) table(predict_anomaly,test2$Target)
Oversampling
Si procede con l’attività inversa oversampling, o sovra-campionamento, eguagliando i valore di 1 a 0 con l’introduzione di nuove osservazioni (aumentando il numero di 1).
set.seed(12345) overfit1=sample(1:nrow(data1),nrow(data0),replace = TRUE) anomalyover=rbind.data.frame(data0,data1[overfit1,]) table(anomalyover$Target) splitt2 <- sample.split(anomalyover,SplitRatio = 0.8) train_over <- subset(anomalyover, split = "TRUE") test_over <- subset(anomalyover, split = "FALSE") anomaly_overfit<-glm(Target~.,data=train_over,family = binomial(link = logit)) anomaly_prev_over<-predict(anomaly_overfit,test_over,type = "response") head(anomaly_prev_over)
prev_over<- ifelse(anomaly_prev_over>0.5,1,0) table(prev_over,test_over$Target)
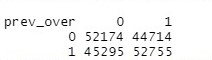
L’obiettivo ultimo di queste analisi è trovare un modello che garantisca meno falsi positivi nella matrice di confusione, in modo tale da fermare la macchina solo al verificarsi di errori certi.
Confrontando le metodologie utilizzate, il modello più efficiente risulta il movimento delle soglie che restituisce meno falsi positivi, di conseguenza, meno interruzioni della macchina durante la lavorazione. Sostanzialmente la movimentazione delle soglie di probabilità permette di scegliere tra approcci più conservativi (quindi meno stop intercettati ma anche meno stop inutili) o, viceversa, approcci più aggressivi.
Ora proseguiremo l’analisi utilizzando questa tecnica su ciascuno dei modelli.
Linear Discriminant Analysis
L’analisi discriminante lineare o LDA, è un metodo di classificazione che fornisce risultati robusti, interpretabili e, tendenzialmente, viene applicato prima di utilizzare altri modelli più complessi.
Dividiamo il dataset in training e test set. La sintassi per l’utilizzo del modello LDA è analoga alla funzione glm() della regressione logistica.
library(tidyverse) library(caret) library(MASS) set.seed(12345) training.individuals <- dataset$Target %>% createDataPartition(p = 0.7, list = FALSE) train_lda <- dataset[training.individuals, ] test_lda <- dataset[-training.individuals, ]
anomaly_lda = lda(formula = Target ~ ., data = train_lda) plot(anomaly_lda)
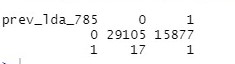
Come nella regressione logistica, effettuiamo una previsione valutando la bontà di adattamento dei dati e analizzando la differenza tra i dati previsti e quelli reali. La soglia più adatta risulta 0.785 (o meglio il 78.5%) e restituisce un solo errore e 17 falsi positivi.
lda_prev=predict(anomaly_lda,test_lda[,-85]) View(classification_metrics(test_lda$Target, prev_lda, step = 0.1)) prev_lda_785= ifelse(lda_prev$posterior[,1]>0.785,1,0) table(prev_lda_785,test_lda$Target)
Confrontando i risultati dei due modelli, la regressione logistica risulta ancora il modello migliore per ora.
Continuiamo l’analisi testando un ultimo modello.
XGBoost
XGBoost è un algoritmo di Machine Learning che implementa alberi di decisione basati su Gradient Boosting. Permette la risoluzione di problemi in modo più accurato e rapido rispetto agli alberi tradizionali.
L’obiettivo di questa libreria è spingere all’estremo dei limiti di calcolo delle macchine per restituire precisione nei risultati.
library(xgboost) library(caret) library(e1071) library(Matrix) library(dplyr) training.individuals <-createDataPartition(dataset$Target,p = 0.7, list = FALSE) train_xgb <- dataset[training.individuals, ] test_xgb <- dataset[-training.individuals, ]
Divisi i dati in training e test set, il modello viene addestrato per l’utilizzo dell’algoritmo.
xgb_train= xgb.DMatrix(data = as.matrix( train_xgb[,-85]),label= as.matrix(train_xgb$Target)) xgb_test <- xgb.DMatrix(data = as.matrix(test_xgb[,-85]), label = test_xgb$Target) watchlist = list(train= xgb_train, test=xgb_test) model = xgb.train(data = xgb_train, max.depth = 3 , watchlist=watchlist, nrounds = 70 ) anomaly_xgb = xgboost(data = xgb_train, max.depth = 3 , nrounds =5, verbose = 0 )
Avvalendoci del training set, constateremo la bontà di adattamento dei dati dell’albero di decisione creato verificandone la sua efficienza. I risultati ottenuti saranno processati dalla funzione classification_metrics() che mostrerà una tabella con tutte le metriche per soglia e verrà scelta la migliore.
xgb_pred <- predict(anomaly_xgb,xgb_test) xgb_pred View(classification_metrics(test_xgb$Target, xgb_pred, step = 0.1)) predict = ifelse (xgb_pred>0.5,1,0 ) table(predict,test_xgb$Target)

La soglia di 0.5 restituisce un solo falso positivo risultando il valore migliore, insieme alla regressione lineare,fin ora ottenuto rispetto ad altri modelli.
Conclusioni
Se all’inizio il modello di regressione logistica risultava fornire i valori migliori restituendo il minor numero di errori, l’algoritmo XGBoost riesce a fare di meglio restituendo un unico errore. Questo breve articolo dimostra come sia possibile praticamente, tramite la Data Science, prevedere il numero di stop di un macchinario.
Scopri di più sui nostri servizi di Data Science!