Data science: l’Energy Management
Data Scientist: lo scienziato dei dati
In questo articolo vedremo cos’è l’Energy Management e come approcciare questo problema tramite la data science. Il caso studio che noi di Diskover ti stiamo per presentare, permette di capire il ruolo e l’importanza dell’analisi dati all’interno di un’impresa. L’analisi che segue è un’attività svolta dal Data Analyst, figura che tramite l’utilizzo dei dati riesce a inquadrare le eventuali problematiche e fornire informazioni utili che possano portare l’impresa a un vantaggio competitivo; sulla base dei risultati ottenuti il Data Scientist ne fornisce un’interpretazione su casistiche real-time basandosi su un modello matematico precedentemente formulato. A tal fine, l’attività del Data Scientist sarà d’aiuto al decision maker nell’intraprendere scelte strategiche che migliorino l’efficienze dell’investimento effettuato. Utilizzando delle strutture simulate andremo a vedere come la forma stessa di un edificio, può impattare notevolmente sul consumo energetico. In particolare, saranno condotte due analisi: analizzeremo carico di riscaldamento e carico di raffreddamento. Il caso studio che noi di Diskover ti stiamo per presentare, permette di capire il ruolo e l’importanza della data science all’interno di un’impresa.
I risultati che si ottengono evidenziano che esiste effettivamente una correlazione tra il consumo di energia e la conformazione dell’edificio.
Cominciamo innanzitutto dalla definizione di Energy management: si intendono tutte quelle attività utili per gestire efficacemente l’energia in una organizzazione (piccola, media o grande), sia essa un’impresa o un qualsiasi altro ente privato/pubblico, con lo scopo di ridurne i consumi e/o aumentarne l’efficienza nell’utilizzo.
In senso esteso, anche un semplice privato potrebbe mettere in atto delle strategie di energy management per gestire i propri consumi energetici individuali, ma solitamente questo aspetto non è incluso nel significato comune attribuito a questo termine. Piuttosto, ci troviamo di fronte all’energy management quando un’organizzazione (privata o pubblica) sta effettuando azioni organizzative, tecniche e comportamentali in modo economicamente corretto, con l’obiettivo di migliorare le sue prestazioni energetiche, mantenendo nel tempo i miglioramenti raggiunti. Sostanzialmente per mettere in atto una seria e corretta azione di energy management in un contesto organizzativo possono essere previste quattro diverse fasi:
1. Raccolta dei dati energetici e misurazione del consumo di energia
2. Analisi dei dati ed individuazione delle opportunità di efficientamento
3. Realizzazione delle azioni
4. Monitoraggio dei progressi e miglioramento continuo
Perché è importante l’Energy Management?
L’Energy Management, come abbiamo visto, è strettamente connesso al miglioramento dei consumi energetici. Le aziende di tutti i settori possono infatti ridurre le spese energetiche per tagliare i propri costi operativi, ma anche per ottenere vantaggi ambientali (riduzione delle emissioni) e ritorni positivi da un punto di vista dell’immagine. Senza dubbio, i requisiti e le pratiche specifiche per ottenere un miglioramento dell’efficienza energetica variano a seconda del settore di appartenenza e delle specificità aziendali, ma esistono una serie di principi fondamentali e di tecniche/tecnologie che possono essere applicati trasversalmente.
Ad esempio, irrinunciabile è una fase di esplorativa iniziale, che permetta di scoprire le eventuali inefficienze interne, ed il successivo monitoraggio dei consumi energetici, ormai sempre più spesso attuato tramite l’impiego soluzioni IoT o digitali. Il presupposto di queste operazioni è che soltanto la conoscenza puntuale dei parametri energetici possa consentire di mettere in atto gli opportuni interventi di efficientamento.
Una volta individuate le anomalie nei consumi è poi possibile intervenire: per quanto riguarda l’illuminazione, qualsiasi organizzazione può dotarsi di lampade e corpi illuminanti più efficienti (come i Led), di dispositivi per la regolazione del flusso, nonché di sensori di luminosità e di presenza. In tutti i contesti è possibile intervenire sulla climatizzazione degli ambienti, rendendola più efficiente con caldaie ad alta efficienza o pompe di calore accoppiate con contabilizzazione, valvole termostatiche, ecc. Un’altra possibilità per un efficace energy management è quella di aumentare l’autonomia energetica interna, investendo nell’autoproduzione: questo significa, quasi sempre, puntare su tecnologie come fotovoltaico e cogenerazione. L’acquisto di motori elettrici di nuova generazione, in particolare nel settore industriale (ma anche nel civile), può consentire consistenti risparmi di elettricità. In ambito trasporti, risparmi consistenti possono essere ottenuti attraverso soluzioni software per la gestione aziendale e la mobilità elettrica/condivisa.
A chi è rivolto?
Come abbiamo descritto in precedenza, Energy Management significa prestare un’attenzione sistematica all’energia con l’obiettivo di migliorare continuamente le prestazioni energetiche delle organizzazioni, pubbliche e private. Non è quindi necessario essere per forza un’azienda industriale per mettere in atto politiche e strategie di energy management. Ancora meno noto è che le utility energetiche, così come le altre società di servizi pubblici, adottino da tempo strategie di energy management per garantire che le loro centrali elettriche e le fonti di energia rinnovabile generino una quantità energia sufficiente per soddisfare la domanda. Un altro errore da non commettere è quello di pensare che l’energy management sia soltanto una questione per le grandi organizzazioni o per le imprese particolarmente energivore. Anche le Pmi, seppure escluse dall’obbligo di nomina di energy manager e dalla diagnosi energetica obbligatoria, possono trarre numerosi benefici dall’adozione di una strategia tesa al risparmio energetico. che può essere effettuata magari appoggiandosi a dei consulenti energetici esterni. Insomma, l’attuazione di una strategia di energy management è fattibile per tutte le organizzazioni, anche se chiaramente i vantaggi sono superiori per quelle aziende che hanno consumi energetici importanti in relazione al proprio fatturato.
Energy efficiency analysis
A questo punto supponiamo di aver aver raccolto i dati di cui necessitiamo. Eseguiremo l’analisi sul carico di riscaldamento, che rappresenta il carico termico da “fornire” per mantenere un edificio ad una temperatura ed umidità prefissate; e sul carico di raffreddamento, ovvero la quantità di energia da “sottrarre” ad un ambiente per mantenerlo ad una temperatura prefissata. Le analisi su queste due variabili saranno condotte utilizzando diverse forme di edifici simulate in Ecotect.
Il dataset puoi trovarlo [qui](https://www.kaggle.com/datasets/elikplim/eergy-efficiency-dataset?select=ENB2012_data.csv) e contiene 8 variabili e 768 righe, che rappresentano edifici strutturati diversamente. Gli edifici differiscono per quanto riguarda le seguenti caratteristiche: l’area vetrata, l’area parete, l’area tetto, la distribuzione dell’area vetrata, l’orientamento, la superficie, la compattezza e altezza totale, mentre le variabili obiettivo sono il carico di riscaldamento e il carico di raffreddamento.
set.seed(17)
df = read.csv("ENB2012_data.csv", header = TRUE)
head(df)
Cosa rappresentano i valori che vedi?
- Compattezza: rapporto tra S e V (tra la superficie esposta all’esterno ed il volume dell’edificio)
- Superficie in m²
- Area parete in m²
- Area tetto in m²
- Altezza totale in m
- Orientamento – 2:North, 3:East, 4:South, 5:West
- Area vetrata in percentuale: 0%, 10%, 25%, 40%
- DistribuzioneAv: distribuzione dell’area vetrata, 1:Uniform, 2:North, 3:East, 4:South, 5:West
- CaricoRiscaldamento in kWh/m²
- CaricoRaffreddamento in kWh/m²
La prima cosa da fare è dividere i dati in base alla variabile obiettivo, perciò creeremo un dataset che ha per variabile obiettivo caricoRiscaldamento ed un altro che ha per obiettivo caricoRaffreddamento.
ris_df<- dplyr::select(df, -caricoRaffreddamento) raf_df <- dplyr::select(df, -caricoRiscaldamento)
Condurremo le due analisi una per volta, cominciando da quella sul carico di riscaldamento.
Analisi del carico di riscaldamento
Supponiamo che un’azienda voglia stimare il consumo di energia in base alle caratteristiche dell’edificio; per fare ciò si possono utilizzare vari tipi di modelli statistici, in particolare, nei casi in cui la variabile obiettivo è quantitativa si utilizzano modelli di regressione.
I diversi modelli di regressione utilizzati sono i seguenti:
- Regressione lineare
- Alberi di Regressione
- Regressione con XGBOOST
Regressione lineare
Cominciamo dalla regressione lineare. Questo è probabilmente il più semplice dei modelli di regressione; riesce a trovare facilmente relazioni lineari tra le variabili e diventa meno utile man mano che le cose si complicano.
mod <- lm(caricoRiscaldamento ~ ., data = ris_df) summary(mod)
Call:
lm(formula = caricoRiscaldamento ~ ., data = ris_df)
Residuals:
Min 1Q Median 3Q Max
-9.8965 -1.3196 -0.0252 1.3532 7.7052
Coefficients: (1 not defined because of singularities)
Estimate Std. Error t value Pr(>|t|)
(Intercept) 84.014521 19.033607 4.414 1.16e-05 ***
compattezza -64.773991 10.289445 -6.295 5.19e-10 ***
superficie -0.087290 0.017075 -5.112 4.04e-07 ***
areaParete 0.060813 0.006648 9.148 < 2e-16 ***
areaTetto NA NA NA NA
altezzaTot 4.169939 0.337990 12.337 < 2e-16 ***
orientamento -0.023328 0.094705 -0.246 0.80550
zonaVetrata 19.932680 0.813986 24.488 < 2e-16 ***
distribuzioneAv 0.203772 0.069918 2.914 0.00367 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.934 on 760 degrees of freedom
Multiple R-squared: 0.9162, Adjusted R-squared: 0.9154
F-statistic: 1187 on 7 and 760 DF, p-value: < 2.2e-16
Come possiamo osservare dall’output del modello di regressione, quasi tutte le caratteristiche sono statisticamente significative, tranne l’orientamento che ha un p-value alto. Dal summary() si può, quindi, dedurre che le caratteristiche impattano sul carico di riscaldamento.
Attraverso il segno dei coefficienti della regressione possiamo affermare che un edificio che si estende in larghezza tende ad avere un consumo di energia minore rispetto ad un edificio che si estende in altezza. La variabile che ci permette di affermare ciò è la compattezza, che esprime il rapporto tra la superficie esposta all’esterno ed il volume dell’edificio. Un edificio caratterizzato da un basso valore di S/V, è energeticamente conveniente perché presenta una minore superficie disperdente per unità di spazio utilizzabile; in conclusione, più un edificio è compatto e migliore possiamo considerarlo dal punto di vista energetico.
Quando si realizza una regressione lineare è importante verificare che le ipotesi che sono alla base del modello siano rispettate. Un modo semplice per verificarlo è attraverso il plot() del modello, che ci mostra in diversi grafici il quartetto di Anscombe.
par(mfrow = c(2,2)) plot(mod)
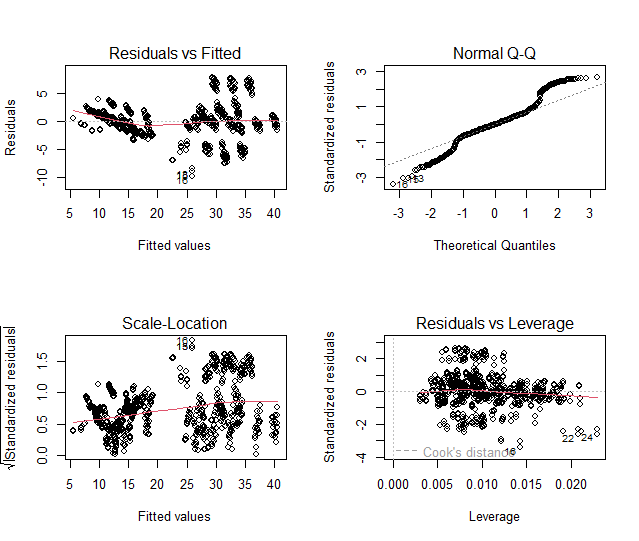
Il primo grafico (“residuals vs fitted“) è un semplice grafico a dispersione tra i valori residui e quelli previsti e sembrerebbe, più o meno, lineare ad eccezione di 3 singoli valori che sono rappresentati in basso(13, 15, 16).
Il secondo (“QQ plot“) è un diagramma di probabilità normale e ci permette di verificare l’assunzione di normalità della distribuzione. Tanto più la nuvola dei punti si sovrappone alla retta che taglia il grafico, tanto più la distribuzione sarà normale. Se i residui sembrano lontani dalla normalità (punti lontani dalla retta), potremmo essere nei guai; in particolare, se il residuo tende ad essere di grandezza maggiore di quello che ci aspetteremmo dalla distribuzione normale, i nostri valori e gli intervalli di confidenza potrebbero essere troppo ottimistici, vale a dire, potremmo non riuscire a tenere adeguatamente conto della piena variabilità dei dati. Nel nostro caso, vediamo un grafico QQ in cui i residui deviano dalla linea diagonale sia nella coda superiore che in quella inferiore e che le code sono osservate come “più pesanti” (hanno valori più grandi) di quanto ci aspetteremmo con le ipotesi di modellazione standard.
Il terzo grafico (“scale-location“) è un approccio più sensibile alla ricerca di deviazioni dall’ipotesi di varianza costante (omoschedasticità). Quando vedi una linea piatta come quella mostrata sopra, significa che i tuoi errori hanno una varianza costante, come suppone il modello; altrimenti, vedrai aprirsi ad imbuto (da sinistra verso destra o viceversa) la nuvola dei punti e questo è un segno di eteroschedasticità.
L’ultimo grafico rappresenta la “distanza di Cook” che permette di individuare valori anomali, outlier oppure punti ad alta leva (che hanno grande impatto sul modello). Vediamo che i punti 16, 22 e 24 hanno una grande influenza sul modello poiché si trovano aldilà della linea rossa.
Leave One Out Cross-Validation
Successivamente, attraverso la Cross-Validation possiamo dividere il dataset e testare l’accuratezza del modello attraverso il Root Mean Squared Error, che sarà la metrica di riferimento per i nostri modelli.
Un tipo molto utilizzato di Cross-Validation è la Leave One Out Cross-Validation, che si basa su una divisione dei dati in due porzioni: una di addestramento ed una di test. Tuttavia, questa operazione viene ripetuta n volte, dove n è il numero di righe del dataset. Questo perché fare un unico test (n=1) vorrebbe dire fidarsi che quel test sia affidabile, mentre ripetere più volte il test significa avere comunque testato il modello ogni volta su valori diversi ed ottenere una buona stima dell’errore.
library(caret)
train.control = trainControl(method = 'LOOCV')
fit.lm = train(caricoRiscaldamento ~ ., data = ris_df, method = 'lm',
trControl = train.control)
fit.lm
## Linear Regression ## ## 768 samples ## 8 predictor ## ## No pre-processing ## Resampling: Leave-One-Out Cross-Validation ## Summary of sample sizes: 767, 767, 767, 767, 767, 767, ... ## Resampling results: ## ## RMSE Rsquared MAE ## 2.948657 0.9144914 2.087867 ## ## Tuning parameter ’intercept’ was held constant at a value of TRUE
Dai risultati puoi vedere che l’RMSE è abbastanza basso, quindi il modello di regressione fa delle previsioni molto accurate o con un errore minimo. Mentre l’R² alto indica che il modello rappresenta in maniera accurata i dati.
Albero di regressione
Passiamo ora al secondo algoritmo che ci permette di effettuare una regressione: gli alberi. Gli algoritmi basati su alberi sono i più utilizzati per via della loro elevata accuratezza su una vasta gamma di casi e poiché risultano molto facili da interpretare.
La libreria caret permette di implementare la logica “Leave-One-Out” anche per gli alberi ed altri tipi di modelli, perciò proseguiremo mantenendo lo stesso approccio anche per il modello basato su alberi. Semplicemente basta cambiare il parametro method, assegnandogli il valore rpart.
library(rpart)
fit.tree = train(caricoRiscaldamento ~ ., data = ris_df, method = 'rpart',
trControl = train.control)
fit.tree
## CART ## ## 768 samples ## 8 predictor ## ## No pre-processing ## Resampling: Leave-One-Out Cross-Validation ## Summary of sample sizes: 767, 767, 767, 767, 767, 767, ... ## Resampling results across tuning parameters: ## ## cp RMSE Rsquared MAE ## 0.02895925 3.741628 0.8626337 2.983031 ## 0.08443700 4.974448 0.7571943 3.938099 ## 0.79108692 9.488863 0.1414265 8.994738 ## ## RMSE was used to select the optimal model using the smallest value. ## The final value used for the model was cp = 0.02895925.
Il modello restituisce un errore del 3%, corrispondente ad un RMSE di 3.74. Ti ricordo che l’RMSE viene calcolato in tutte le n iterazioni, quindi il valore risultante è da considerare come media dei valori ottenuti nelle singole iterazioni.
library(rattle) fancyRpartPlot(fit.tree$finalModel)
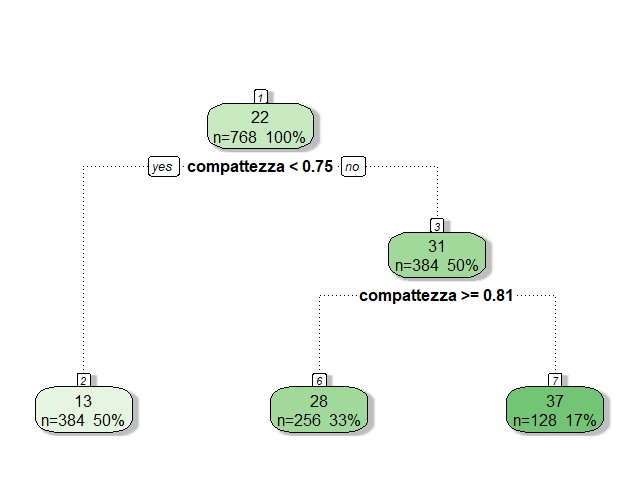
Come notiamo dalla figura la variabile da cui parte l’albero è la superficie e di conseguenza è la caratteristica più importante per l’albero, questo perché gli alberi di regressione vanno letti dall’alto verso il basso. Successivamente l’albero si divide in due rami che andranno a loro volta a formare dei nodi con altre caratteristiche. Nelle foglie compaiono i risultati intermedi della variabile obiettivo per la soglia di quella determinata caratteristica, ossia all’interno delle foglie abbiamo la media della variabile obiettivo per una soglia stimata in base all’RSS più basso di quella determinata variabile indipendente. Tutte le altre caratteristiche possiamo ritenerle non importanti per l’albero poiché non compaiono nel modello.
XGBOOST
L’ultimo modello che vedremo è: XGBOOST. Si tratta di un metodo avanzato per fare regressione (e classificazione). Senza dubbio è uno degli strumenti più utilizzati, potenti ed efficaci che si possano trovare; si tratta di metodo basato su alberi ma che è pensato per superare le problematiche che anche questi modelli hanno. La libreria caret offre un’implementazione facilissima di questo algoritmo. Anche stavolta bisogna cambiare il parametro method, ma in xgbTree.
Tieni sempre a mente la logica usata fino ad ora perché ad essa aggiungeremo una componente in questo modello. Si genererà una griglia di possibili parametri del modello e si faranno di tentativi per cercare la combinazione migliore di essi. Questa procedura, che viene chiamata hyperparameter tuning, permette di trovare la configurazione del modello che meglio si adatta ai dati a disposizione; ne risulterà, perciò, un modello più accurato.
library(xgboost)
tune_grid <- expand.grid(nrounds = c(50),
max_depth = c(5,15),
eta = c( 0.05),
gamma = c( 0.01),
colsample_bytree = c(0.2,0.75),
min_child_weight = c(0.05),
subsample = c(0.2, 0.75))
fit.xgb <- train(caricoRiscaldamento ~ .,
data = ris_df,
method = 'xgbTree',
trControl = train.control,
tuneGrid = tune_grid,
tuneLength = 2)
fit.xgb
## eXtreme Gradient Boosting ## ## 768 samples ## 8 predictor ## ## No pre-processing ## Resampling: Leave-One-Out Cross-Validation ## Summary of sample sizes: 767, 767, 767, 767, 767, 767, ... ## Resampling results across tuning parameters: ## ## max_depth colsample_bytree subsample RMSE Rsquared MAE ## 5 0.20 0.20 4.111855 0.9441155 2.982724 ## 5 0.20 0.75 3.923807 0.9514190 2.846300 ## 5 0.75 0.20 2.470953 0.9876884 1.942967 ## 5 0.75 0.75 2.137104 0.9950264 1.788463 ## 15 0.20 0.20 4.104712 0.9429719 2.972661 ## 15 0.20 0.75 3.915185 0.9490937 2.851743 ## 15 0.75 0.20 2.475879 0.9882245 1.947935 ## 15 0.75 0.75 2.126948 0.9954610 1.794925 ## ## Tuning parameter ’nrounds’ was held constant at a value of 50 ## Tuning ## ’gamma’ was held constant at a value of 0.01 ## Tuning ## parameter ’min_child_weight’ was held constant at a value of 0.05 ## RMSE was used to select the optimal model using the smallest value. ## The final values used for the model were nrounds = 50, max_depth = 15, eta ## = 0.05, gamma = 0.01, colsample_bytree = 0.75, min_child_weight = 0.05 ## and subsample = 0.75. 5
Vedendo i valori dell’R² e del root mean square error possiamo affermare che il modello è molto preciso ed effettua delle previsioni giuste con un errore di stima molto basso e ,inoltre, i predittori spiegano quasi il 100% della variabilità della nostra y.
Analisi del carico di raffreddamento
Una volta conclusa l’analisi sul carico di riscaldamento passiamo al secondo oggetto della nostra attenzione: il carico di raffreddamento. Le variabili esplicative sono esattamente le stesse dell’analisi precedente; ad essere cambiata è solo la variabile obiettivo.
Regressione lineare
Cominciamo dalla regressione lineare e vediamo quali sono i risultati.
mod.raf <- lm(caricoRaffreddamento ~ ., data = raf_df) summary(mod.raf)
## ## Call: ## lm(formula = caricoRaffreddamento ~ ., data = raf_df) ## ## Residuals: ## Min 1Q Median 3Q Max ## -8.6940 -1.5606 -0.2668 1.3968 11.1775 ## ## Coefficients: (1 not defined because of singularities) ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 97.245749 20.764711 4.683 3.34e-06 *** ## compattezza -70.787707 11.225269 -6.306 4.85e-10 *** ## superficie -0.088245 0.018628 -4.737 2.59e-06 *** ## areaParete 0.044682 0.007253 6.161 1.17e-09 *** ## areaTetto NA NA NA NA ## altezzaTot 4.283843 0.368730 11.618 < 2e-16 *** ## orientamento 0.121510 0.103318 1.176 0.240 ## zonaVetrata 14.717068 0.888018 16.573 < 2e-16 *** ## distribuzioneAv 0.040697 0.076277 0.534 0.594 ## --- ## Signif. codes: 0 ’***’ 0.001 ’**’ 0.01 ’*’ 0.05 ’.’ 0.1 ’ ’ 1 ## ## Residual standard error: 3.201 on 760 degrees of freedom ## Multiple R-squared: 0.8878, Adjusted R-squared: 0.8868 ## F-statistic: 859.1 on 7 and 760 DF, p-value: < 2.2e-16
Come possiamo osservare dall’output del modello di regressione, tutte le caratteristiche sono statisticamente significative, tranne l’orientamento; come era per il caso del carico di riscaldamento. Dal summary() si può, quindi, dedurre che le caratteristiche impattano sul carico di raffreddamento.
par(mfrow = c(2,2)) plot(mod)
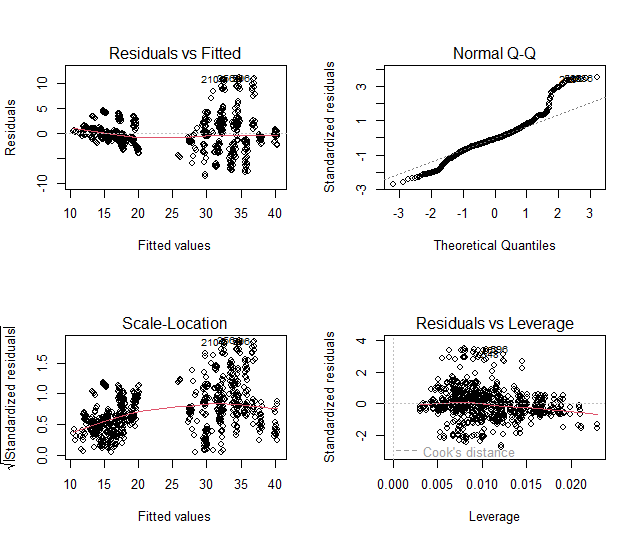
Il primo grafico (“residuals vs fitted“) è un semplice grafico a dispersione tra i valori residui e quelli previsti e sembrerebbe, più o meno, lineare ad eccezione di 3 singoli valori che sono rappresentati in alto(210, 356 , 596).
Il secondo (“QQ plot“) è un diagramma di probabilità normale e ci permette di verificare l’assunzione di normalità della distribuzione. Tanto più la nuvola dei punti si sovrappone alla retta che taglia il grafico, tanto più la distribuzione sarà normale. Anche in questo caso, vediamo un grafico QQ in cui i residui deviano dalla linea diagonale, in particolare nella parte superiore.
Il terzo grafico (“scale-location“) è un approccio più sensibile alla ricerca di deviazioni dall’ipotesi di varianza costante. Sembra esserci dell’eteroschedasticità anche questa volta.
L’ultimo grafico rappresenta la “distanza di Cook” che permette di individuare valori anomali, outlier oppure punti ad alta leva (che hanno grande impatto sul modello). Non si identificano particolari outlier anche se la nuvola di punti non è ottimale.
Mettiamo alla prova il modello sulla previsione del consumo, utilizzando ancora una volta la libreria caret. I comando ormai dovrebbero esserti familiari e facili da comprendere.
train.control = trainControl(method = 'LOOCV')
fit.lm.raf = train(caricoRaffreddamento ~ ., data = raf_df, method = 'lm',
trControl = train.control)
fit.lm.raf
## Linear Regression ## ## 768 samples ## 8 predictor ## ## No pre-processing ## Resampling: Leave-One-Out Cross-Validation ## Summary of sample sizes: 767, 767, 767, 767, 767, 767, ... ## Resampling results: ## ## RMSE Rsquared MAE ## 3.21563 0.8855993 2.265381 ## ## Tuning parameter ’intercept’ was held constant at a value of TRUE
Dai risultati puoi vedere che l’RMSE è abbastanza basso, quindi il modello di regressione fa delle previsioni molto accurate o con un errore minimo. Mentre l’R² alto indica che il modello rappresenta in maniera accurata i dati.
Albero di regressione
Passiamo all’implementazione di un albero di regressione per il carico di raffreddamento.
fit.tree.raf = train(caricoRaffreddamento ~ ., data = raf_df, method = 'rpart',
trControl = train.control)
fit.tree.raf
## CART ## ## 768 samples ## 8 predictor ## ## No pre-processing ## Resampling: Leave-One-Out Cross-Validation ## Summary of sample sizes: 767, 767, 767, 767, 767, 767, ... ## Resampling results across tuning parameters: ## ## cp RMSE Rsquared MAE ## 0.01885084 3.527129 0.8626047 2.844942 ## 0.07534417 4.559960 0.7707271 3.590212 ## 0.80243107 9.053001 0.1288554 8.585410 ## ## RMSE was used to select the optimal model using the smallest value. ## The final value used for the model was cp = 0.01885084.
Il modello restituisce un errore poco più alto del 2.8%, corrispondente ad un RMSE di 3.52. Ti ricordo che l’RMSE viene calcolato in tutte le n iterazioni. quindi il valore risultante è da considerare come media dei valori ottenuti nelle singole iterazioni.
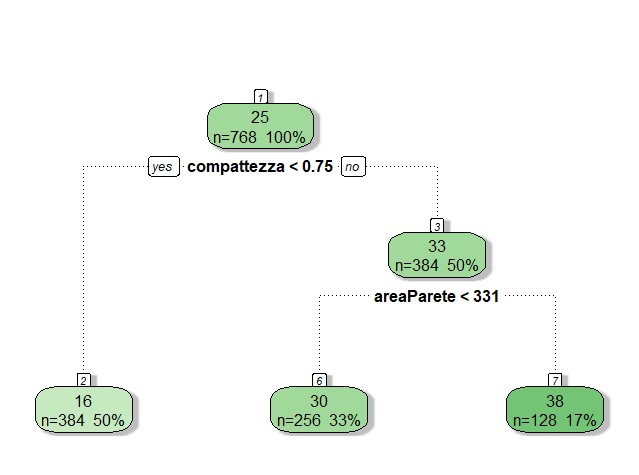
Come notiamo dalla figura la variabile da cui parte l’albero è la superficie e di conseguenza è la caratteristica più importante per l’albero, questo perché gli alberi di regressione vanno letti dall’alto verso il basso.
Successivamente l’albero si divide in due rami che andranno a loro volta a formare dei nodi con altre caratteristiche. Nelle foglie compaiono i risultati intermedi della y per la soglia di quella determinata caratteristica. Ossia all’interno delle foglie abbiamo la media della y per una soglia stimata in base all’RSS più basso di quella determinata variabile indipendente. Tutte le altre caratteristiche possiamo ritenerle non importanti per l’albero poiché non compaiono nel modello.
XGBOOST
In ultimo, ancora una volta c’è XGBOOST. Riutilizzo la griglia creata in precedenza anche per questo modello.
fit.xgb.raf <- train(caricoRaffreddamento ~ .,
data = raf_df,
method = 'xgbTree',
trControl = train.control,
tuneGrid = tune_grid,
tuneLength = 10)
fit.xgb.raf
## eXtreme Gradient Boosting ## ## 768 samples ## 8 predictor ## ## No pre-processing ## Resampling: Leave-One-Out Cross-Validation ## Summary of sample sizes: 767, 767, 767, 767, 767, 767, ... ## Resampling results across tuning parameters: ## ## max_depth colsample_bytree subsample RMSE Rsquared MAE ## 5 0.20 0.20 4.130968 0.9253871 2.810992 ## 5 0.20 0.75 3.952343 0.9353386 2.690136 ## 5 0.75 0.20 3.055809 0.9589747 2.229346 ## 5 0.75 0.75 2.772750 0.9663009 2.056483 ## 15 0.20 0.20 4.120590 0.9261183 2.827933 ## 15 0.20 0.75 3.953162 0.9341685 2.677161 ## 15 0.75 0.20 3.058231 0.9599263 2.224414 ## 15 0.75 0.75 2.752473 0.9687737 2.055758 ## ## Tuning parameter ’nrounds’ was held constant at a value of 50 ## Tuning ## ’gamma’ was held constant at a value of 0.01 ## Tuning ## parameter ’min_child_weight’ was held constant at a value of 0.05 ## RMSE was used to select the optimal model using the smallest value. ## The final values used for the model were nrounds = 50, max_depth = 15, eta ## = 0.05, gamma = 0.01, colsample_bytree = 0.75, min_child_weight = 0.05 ## and subsample = 0.75. 96
Vedendo i valori dell’R² e del root mean square error possiamo affermare che il modello è molto preciso ed effettua delle previsioni giuste con un errore di stima molto basso. Inoltre, i predittori spiegano circa il 97% della variabilità della nostra y.
Conclusione
Fatte le precedenti dichiarazioni possiamo concludere che, i modelli utilizzati hanno permesso di valutare l’impatto delle variabili sia in situazioni di risaldamento che raffreddamento. Ci sono variabili che hanno inciso maggiormente rispetto a altre come: la compattezza e la superficie. Nell’analisi fatta sulle variabili d’impatto del riscaldamento dell’edificio utilizzando modelli di classificazione come regressione lineare, alberi di decisione e XGBoost, abbiamo riscontrato che tutti restituiscono un’ottima capacità di adattamento ai dati. Infatti dal summary() della regressione lineare otteniamo un R² molto alto pari a 0.912. I risultati della classificazione con alberi di decisione è stata confermata la forte incidenza della “compattezza” sul riscaldamento rispetto alle altre variabili. Il modello XGBoost risulta essere il modello più adatto e esaustivo, in grado di fornire una previsione con un errore di stima molto basso. Per quando riguarda l’analisi sul raffreddamento i risultati ottenuti sono più o meno simili riscontrando un’ottima capacità di adattamento dei dati e previsioni con errori molto bassi nel modello XGBoost.
Scopri di più sui nostri servizi di Data Science!